
Table of Contents
Project Overview
Delivery delays are a major driver of customer dissatisfaction, often resulting in negative reviews and, ultimately, churn. In a previous project analyzing customer behavior using the Olist e-commerce dataset, I identified logistics issues impacting the customer experience. Here, I address those issues by building a machine learning model, powered by XGBoost, to predict delivery delays and help logistics teams reducing late shipments.
My analysis aims at answering the following questions:
- Which factors related to orders, logistics, and customers have the greatest impact on whether a delivery is late?
- Do temporal patterns influence delivery performance?
- What actionable steps can be taken to prevent future delivery delays?
Working Datasets
-
This analysis uses the Olist Brazilian E-commerce dataset , which originally comprises nine relational tables covering orders, customers, products, sellers, payments, and reviews. For efficient exploration and modeling, these tables were cleaned, merged, and transformed in a previous data-pipeline project, resulting in three Analytical Base Tables (ABTs) focusing on orders, customers, and products. This project focuses on the order-level dataset.

Feature Engineering
-
Target variable:
The model aims at predictingis_late(0 or 1), derived from the difference between the actual delivery date and the estimated delivery date. -
Candidate features:
Based on the original dataset, I engineered a set of predictors capturing temporal patterns, economic behavior, logistics complexity, and customer loyalty:
| Feature | Source | Computation Method |
|---|---|---|
| Temporal | order purchase timestamp | Extract year/month/hour components |
| is_weekend | Day of week | Binary flag for Sat/Sun |
| is_holiday_season | Month | Binary flag for Nov/Dec |
| approval_delay_hours | Timestamps | approved_at − purchase_timestamp |
| carrier_pickup_days | Timestamps | carrier_date − approved_at |
| freight_percentage | Price ratio | (freight / price) × 100 |
| total_order_value | Price | price + freight_value |
| revenue_per_km | Price + distance | price / distance_km |
| is_high_value | Threshold | Top 10% quantile flag |
| customer_order_count | Aggregation | Count orders per customer_unique_id |
| days_since_last_order | Date difference | dataset_end − last_order_date |
| distance_km | Geospatial calculation | Geodesic distance (seller ↔ customer) |
| distance_category | Binning | Distance discretized into 4 categories |
-
Redundant Features and Data Leakage:
To simplify the model and improve generalization, highly correlated features (correlation coefficient > 0.7) were removed. Additionally, variables that were directly derived from the target, or reflecting information that would not be available at prediction time, was excluded to prevent data leakage. -
Encodings:
Categorical variables including less that 50 levels were one-hot-encoded to improve model interpretability.
Modeling Approach
I used a Gradient Boosting approach (XGBoost) for predicting delivery delays because it is well suited to model complex, non-linear relationships in structured data (typical of logistics datasets). Moreover, it handles real-world messy data (skewed distribution, outliers, missing values, etc) very well, and is widely recognized as one of the top-performing algorithms for tabular classification.
-
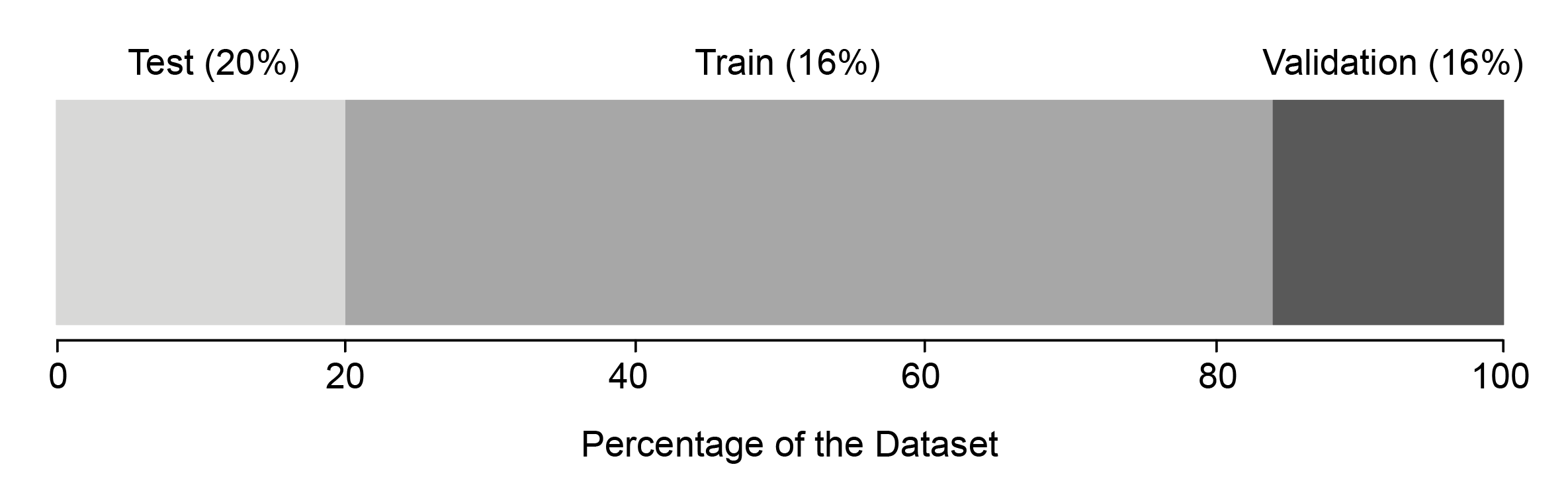
Data Splitting:
The dataset of 95,936 orders was divided into training, validation, and test subsets to train, tune, and evaluate the model respectively.
-
Hyper parameter tuning:
Initially, early stopping was applied to identify the optimal number of boosting rounds and mitigate overfitting. Second, a randomized search was conducted to optimize key hyperparameters of the XGBoost model, further improving predictive performance and generalization.
Model Evaluation
The final XGBoost model achieved a ROC AUC score of 0.84 on the unseen test set. This indicates that the model can correctly predict whether a delivery will be late 84% of the time.
In spite of this strong overall performance, the model faced a challenge due to the class imbalance in the dataset, with late deliveries representing about 10% of all orders. This imbalance likely caused the model to focus more on predicting on-time deliveries correctly while missing some late ones. To better identify at-risk shipments, future iterations could adjust class weights, use recall-oriented metrics, or apply resampling techniques to give the minority class greater importance during training.
Feature Importance & Insights
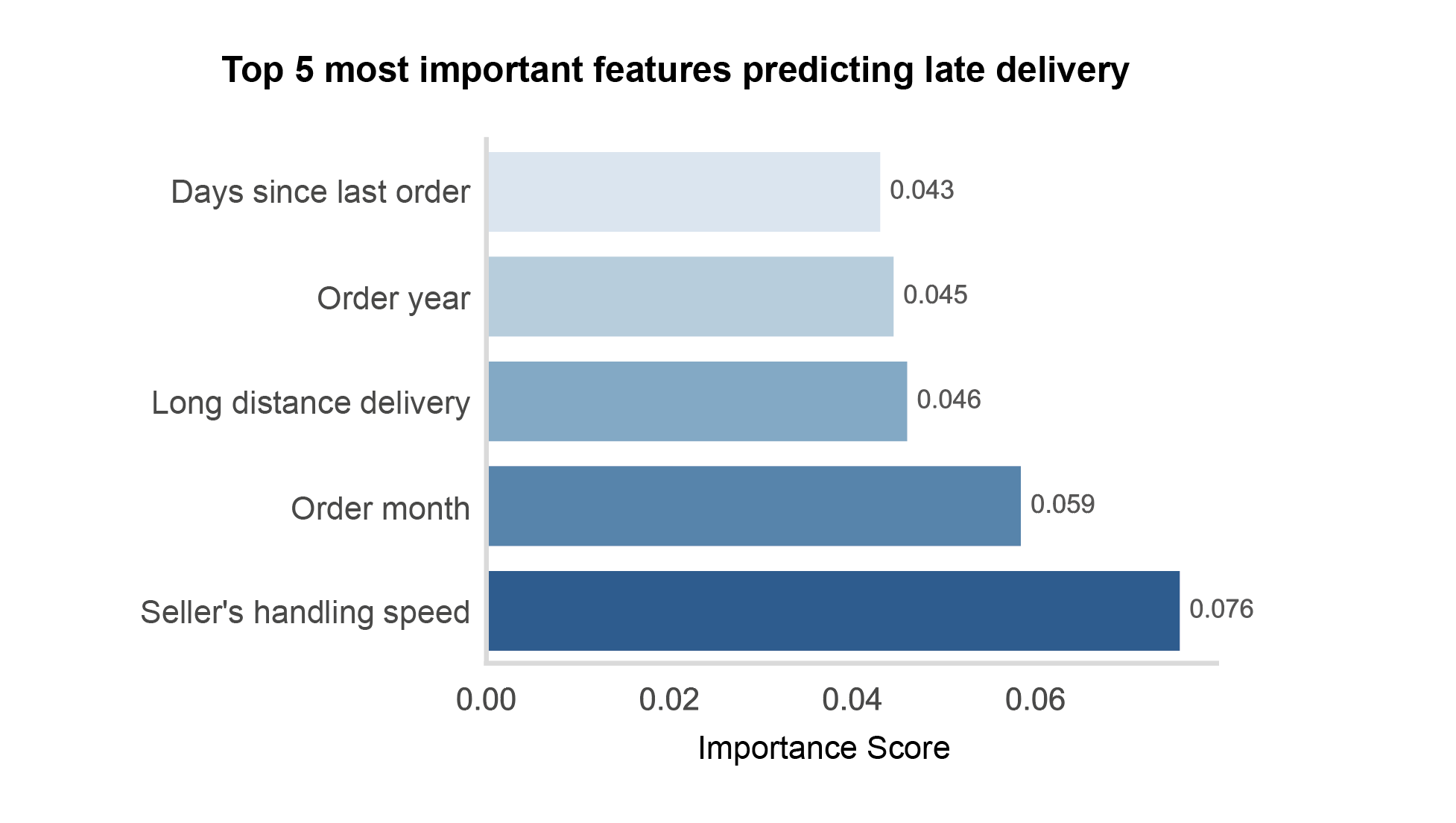
The model identified the seller’s handling speed as the strongest predictor of delivery delays (an intuitive result). Although not directly controllable, the company could prioritize or incentivize sellers with faster processing times.
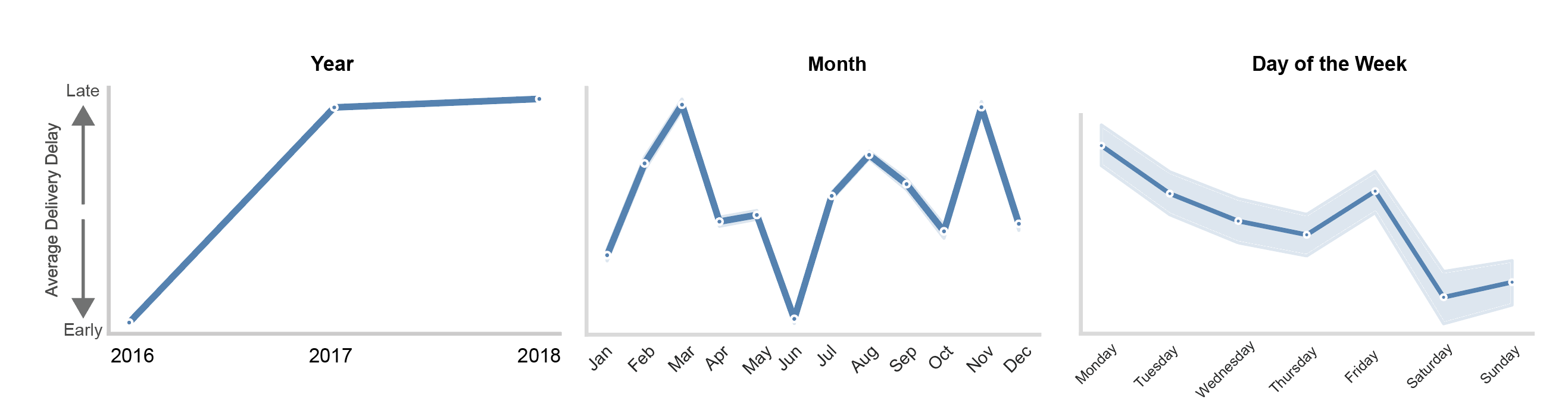
- Temporal Patterns:
-
Temporal dynamics played a significant role in predicting delivery delays.
In Olist’s early development phase (2016), deliveries were generally faster, but delays increased as the company scaled.
Seasonality also emerged: delays peaked in March and November, while June showed the most on-time deliveries.
Additionally, orders placed on Fridays tended to experience slightly longer delays.
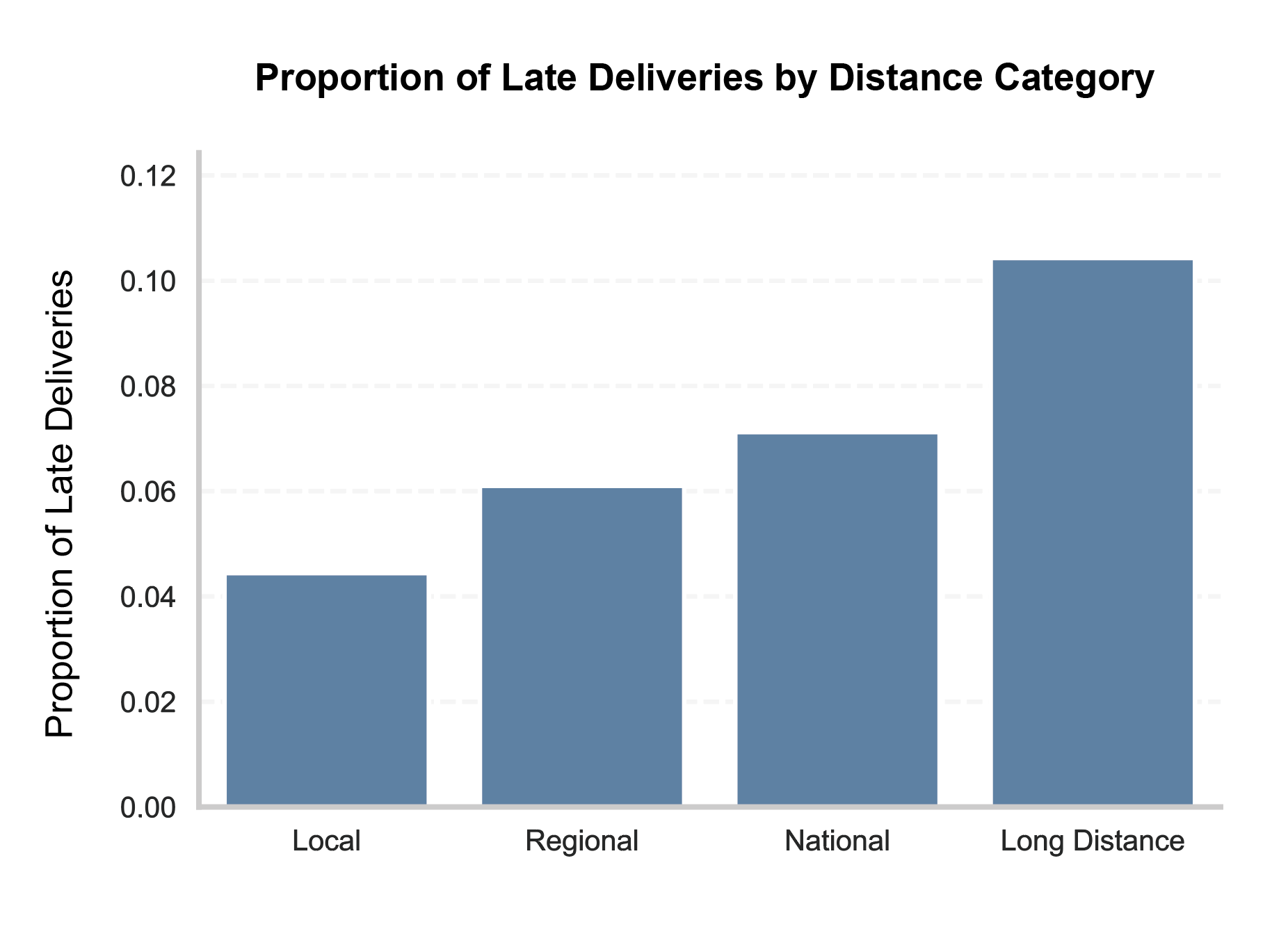
- Geographic Distance:
-
Delivery delays tend to increase with distance. While this is an intuitive pattern, it highlights an issue in the delivery date estimation process, which appears to insufficiently account for distance.
- Customer Recency:
- Orders placed by customers who have been inactive for a long time show a lower likelihood of late delivery. While the factors underlying this pattern warrant further investigation, it most likely reflects the temporal trend observed earlier in the analysis.
Conclusion and Insights
This project successfully demonstrated how supervised machine learning, using the XGBoost gradient boosting algorithm, can be applied to predict delivery delays in an e-commerce context. By leveraging historical order data, the model achieved strong performance, correctly predicting delay in 84% of the orders.
The feature importance analysis revealed that delays are mainly driven by seller handling time, logistics distance, and temporal factors such as seasonality and order day. Based on this analysis, the following recommendations were developed to help the company reduce late deliveries and improve operational efficiency.
Actionable Recommendations
-
Improve seller handling performance:
Seller processing time was the strongest driver of late deliveries. The company could:- Set performance benchmarks and monitor average handling delays per seller.
- Prioritize or promote sellers with consistently fast order preparation.
- Offer incentives, training, or operational support to slower sellers.
-
Refine delivery time estimation by distance:
The model revealed that the current estimated delivery times do not fully account for geographic distance.- Adjusting delivery date estimations based on seller–customer distance categories could make predictions more realistic and reduce perceived lateness.
-
Plan logistics around temporal patterns:
Delays increase during certain months (March, November) and days (Fridays). The company could:- Increase carrier capacity or staffing during seasonal peaks.
- Communicate adjusted delivery expectations for orders placed before weekends.
- Use predictive modeling to forecast upcoming peaks in demand or delay risk.
Perspective to improve the model
- The current model relies entirely on past order records, without incorporating real-time contextual factors such as traffic conditions or weather events that can heavily influence delivery times. A more accurate prediction of delay could be achieved by incorporating those factors in further analyses.
- Enriching the model with geolocation features and external data sources such as regional infrastructure or weather patterns would further strengthen its predictive power.